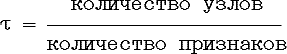![]()
Fuzzy graph-schemes in pattern recognition © 1992 Dmitry A.Kazakov
5. Система нечеткого обучения на основе граф-схем
Система нечеткого обучения на основе граф-схем реализована на языке программирования Ada под управлением операционной системы VAX/VMS. Объем комплекса составляет порядка 9000 строк исходного текста.
5.1. Обоснование выбора языка реализации
В качестве языка реализации системы нечеткого обучения был выбран язык Ada [Дже88]. Каковы причины предпочтения, оказанного языку Ada перед другими широко распространенными языками программирования, такими как Basic, C, FORTRAN, Modula-2, Pascal, PL/1?
5.1.1. Переносимость
Одним из основных требований к разрабатываемой системе было требование переносимости. Предполагалось, что помимо VAX/VMS она должна функционировать в MS-DOS на IBM PC. Язык Ada является в настоящее время единственным реально переносимым языком. Это обеспечивается наличием, как тщательно разработанного стандарта (ANSI/MIL-STD-1815 A) не только на сам язык Ada в узком понимании, но и в широком смысле, т.е. на систему программирования Ada, так и жестким контролем за его соблюдением со стороны AJPO (Ada Joint Program Office). Любой компилятор Ada должен иметь сертификат AJPO, подтверждающий его соответствие стандарту. В отличие от C и тем более от Pascal в языке Ada существует стандартное окружение, включающее в себя пакеты ввода-вывода достаточно высокого уровня, чтобы не использовать системно-зависимых средств.
5.1.2. Надежность
Требование надежности математического обеспечения выходит на первый план в таких больших по объему продуктах, каковой является разрабатываемая система. Существует критический объем программного продукта, после которого уже невозможно контролировать распространение ошибок из ненадежных его частей. Язык Ada - язык жесткой типизации, наиболее полно удовлетворяющий требованиям надежности [Янг85]. Из перечисленных выше языков только Pascal и Modula-2 жестко типизованы. Однако это их свойство часто является скорее помехой нежели подспорьем из-за бедности языковых конструкций, не позволяющих, например, иметь строки переменной длины. Поэтому обычная практика программирования на Pascal заключается в использовании всевозможных трюков для взламывания защиты типов, что ведет к снижению надежности языка.
Отсутствие стандартов и их поддержки ведет к тому, что большая часть компиляторов, функционирующих в MS-DOS имеют ошибки, иногда достаточно тяжелые, как в Pascal 6.0 фирмы Borland.
.5.1.3. Мощность
Система нечеткого обучения, включающая в себя диалоговые средства, синтаксический анализ, систему управления базой данных, чисто вычислительные модули и динамические структуры данных, требует для своей реализации почти полный набор средств, предоставляемых языком Ada:
Средства объектно-ориентированного программирования языка Ada (настраиваемые модули и пакеты) позволяют достичь высокого уровня абстракции при написании функциональных частей системы.
5.1.4. Эстетические соображения
Язык Ada - современный язык программирования, впитавший в себя лучшие конструкции своих предшественников. Программист вынужден возиться с метками, работая на FORTRAN, продираться сквозь дебри звездочек и фигурных скобок в C и тщательно пересчитывать операторы end в Pascal и PL/1. Конструкции языка Ada просты и изящны - параметр цикла автоматически объявляется и локален внутри цикла, указатели индексируются так же как и данные, на которые они указывают, везде где может стоять один оператор, можно разместить несколько операторов и т.п.
5.2. Обоснование выбора операционной системы
Система нечеткого обучения была разработана в среде операционной системы VAX/VMS фирмы DEC (Digital Equipment Corporation). Среди широко распространенных и доступных в нашей стране операционных систем VAX/VMS является наиболее современной и мощной. Она обладает:
Операционная система VAX/VMS функционирует на отечественных машинах типа СМ-1700.
С появлением сертифицированных компиляторов Ada для MS-DOS система нечеткого обучения будет перенесена на машины IBM PC.
5.3. Вопросы реализации
Для реализации алгебры уровней принадлежности нечеткого множества естественно испльзовать либо фиксированный, либо целый тип. Описание типа уровня принадлежности, в первом случае, будет:
type BELONGING_LEVEL is delta 1.0/LEVEL_OF_TRUTH range 0.0..1.0;
а во втором:
type BELONGING_LEVEL is new INTEGER range 0..LEVEL_OF_TRUTH;
Здесь константа LEVEL_OF_TRUTH задает степень дискретизации уровней принадлежности нечеткого множества. Для практических целей достаточно 100 уровней дискретизации. Механизм совмещения имен языка Ada позволяет использовать имена операций and, or, xor, not для логических функций. Например, функция, реализующая логическое ИЛИ может быть описана, как
function "and" (A, B :BELONGING_LEVEL) return BELONGING_LEVEL;
Из двух традиционных вариантов реализации множеств - списка и битовой карты - следует выбрать последний, так как активное применение операции дополнения делает необходимым хранение уровней принадлежности почти всех точек базового множества. Язык Ada предлагает широкий выбор описаний нечеткого множества:
Во-первых, настраиваемый тип с параметром настройки, задающим тип базового множества:
generic
type INDEX is (<>);
type FUZZY_SET is array (INDEX) of
BELONGING_LEVEL;.
Здесь INDEX - формальный параметр настройки, его фактическое значение - любой перечислимый тип. Подобный подход, пожалуй, наиболее естественен, но несколько громоздок, так как пакет, реализующий алгебру нечетких множеств получается настраиваемым.
Во-вторых, именуемый тип с дискриминантом, задающим мощность базового множества:
type FUZZY_SET (CARD:POSITIVE) is
record
MAP: array (POSITIVE range
1..CARD) of BELONGING_LEVEL;
end;
Описание нечеткого множества будет иметь вид A:FUZZY_SET(20); Этот подход неудобен сложностью доступа к уровням принадлежности отдельных точек носителя (необходимо явно специфицировать компоненту MAP). Кроме того, затруднено формирование вырезок (ограничений функции принадлежности на подмножестве базового множества).
В-третьих, неограниченный индексируемый тип:
type FUZZY_SET is array (POSITIVE) of BELONGING_LEVEL;
В этом случае описание нечеткого множества принимает вид: A:FUZZY_SET(1..20);. Пакет, реализующий алгебру нечетких множеств использует именно этот вариант. Имена функций объединения, пересечения и т.п. совмещены с операциями or, and и т.д. Поэтому, например, пересечение множеств A и B записывается просто как A and B.
Граф-схема в системе нечеткого обучения реализована в виде двунаправленного списка узлов. Тип GRAPH_NODE, описывающий узел граф-схемы - именуемый вариантный тип с дискриминантами, задающими мощность области значений проверяемого узлом признака и количество исходящих дуг. Он описывается рекурсивно:
type TYPE_OF_GRAPH_NODE is (BRANCH,CLASS);Для реализации обхода графа дескриптор признака содержит структуру данных обеспечивающую последовательное разбиение области значений признака на подъинтервалы. Пакет BINARIZED_INTERVAL реализует примитивы обхода графа: NEXT, DOWN, UP.
Работа с терминалом представляет определенную проблему, так как стандартное окружение не содержит пакетов, подобных CURSES в языке C. Для того, чтобы локализовать использование системно-зависимых средств работы с терминалом (таких как библиотека SMG в VAX/VMS), весь нижний уровень ввод-вывода сведен в один пакет:
package LOW_LEVEL_TERMINAL_IO is
type DOT is
-- Point
record
X
:INTEGER;
Y
:INTEGER;
end record;
type BOX is
--
Rectangle
record
L_U
:DOT;
R_D
:DOT;
end record;
type COLOR is (BLACK,GRAY,WHITE); -- Colors
type SINGLE_KEY is new
INTEGER; -- Keyboard key
KEYBOARD_INTERRUPT :exception; --
Key-press
function GET_SINGLE_KEY
return SINGLE_KEY;
procedure HIDE_COURSOR;
procedure
SHOW_COURSOR(AT_DOT :in DOT;
INS_MODE:in
BOOLEAN:=FALSE);
procedure
TEST_KEYBOARD;
procedure CLEAN
(RECTANGLE
:in BOX);-- Clean
procedure SHADOW
(RECTANGLE :in BOX; -- Paint
COLOR_MODE
:in COLOR);
procedure
UNGET(PASTING_KEY :in SINGLE_KEY);
procedure OUTPUT(LINE :in STRING;
-- Text output
AT_DOT
:in DOT;
INVERSE
:in BOOLEAN:=FALSE;
BOLD
:in BOOLEAN:=FALSE);
procedure BELL;
procedure SHUTDOWN;
end LOW_LEVEL_TERMINAL_IO;
Такой пакет может быть легко реализован в любом окружении.
При реализации переносимой базы данных основная проблема - повышение эффективности ввода-вывода. Так как в стандартном окружении отсутствуют индексные файлы, ввод-вывод осуществляется блоками фиксированной длины в нетипизованные файлы прямого доступа. Для VMS оптимальный размер блока кратен 512 байтам. Наибольший объем ввода-вывода связан с обучающим множеством. Для снижения затрат на физический обмен с диском нечеткие множества храняться в упакованном формате. Кроме того, обучающие примеры накапливаются в буфере, что позволяет исключить повторное чтение их с диска. Каждое обучающее множество организовано в виде набора файлов. Количество одновременно открытых файлов ограничено системным окружением. Поэтому система управления базой данных динамически перераспределяет каналы ввода-вывода, стараясь держать открытыми наиболее часто используемые файлы.
Еще одной проблемой было использование кирилицы в диалоге на русском языке. Решение этой проблемы лежит в двух направлениях. Если реализация языка Ada отводит под тип CHARACTER целый байт, можно просто упаковать в него восьмибитные коды, неконтролируемым преобразованием типа (с помощью процедуры UNCHECKED_CONVERSION). При семибитном CHARACTER можно либо использовать символы SI/SO для переключения регистров, либо заместить тип CHARACTER своей реализацией.
5.4. Структура системы нечеткого обучения
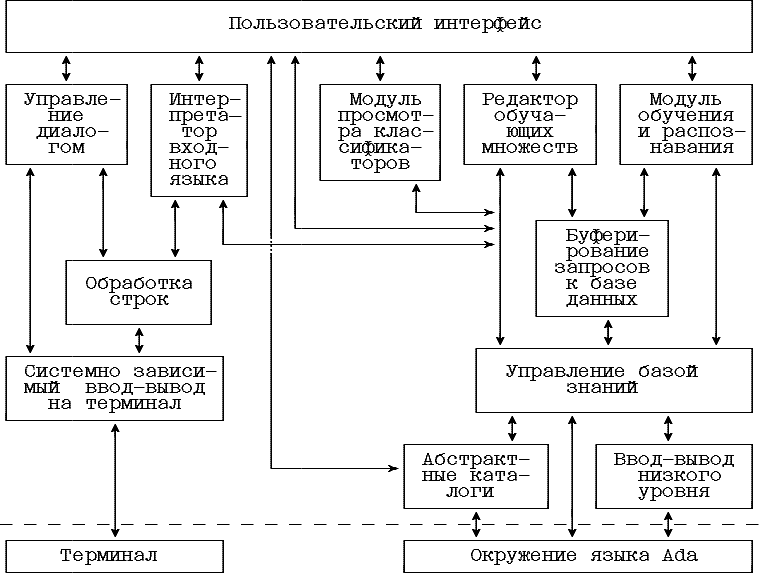
Составные части системы нечеткого обучения показаны на рис. 5.1.
Рис. 5.1. Структура системы нечеткого обучения
Пользовательский интерфейс принимает и удовлетворяет запросы пользователя. Модуль управления диалогом реализует различные формы диалога: меню, запросы и т.п. Интерпретатор входного языка предназначен для ввода данных, поступающих из последовательного потока. Модуль просмотра классификаторов позволяет просмотреть граф-схему на пользовательзовательском терминале. Редактор обучающих множеств предназначен для экранного редактирования обучающих примеров. Модуль обучения и распознавания обеспечивает построение и использование классификаторов. Буферирование запросов к базе знаний представляет собой кэш-память, снижающую потребность в физическом вводе-выводе при обращении к базе знаний. Модуль обработки строк предоставляет ряд операций по редактированию символьных строк. Модуль системно-зависимого ввода-вывода на терминал содержит примитивы для работы с терминалом. В операционной системе VAX/VMS он использует системную резидентную библиотеку SMG (Screen ManaGement) работы с терминалом и, поэтому не зависит от типа терминала. При переносе в другую операционную систему только этот модуль требует внесения изменений. Абстрактные каталоги содержат универсальный интерфейс для обработки каталогов базы знаний. Ввод-вывод низкого уровня обеспечивает эффективный обмен системы управления базой знаний с диском.
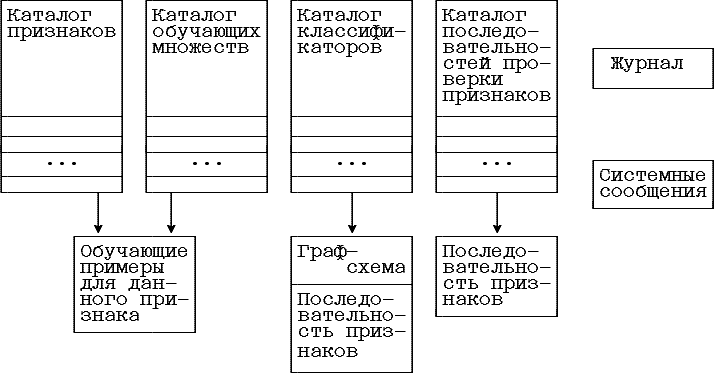
Структура базы знаний представлена на рис. 5.2.
Рис. 5.2. Структура базы знаний системы нечеткого обучения
Каталог признаков содержит описания всех признаков и классов, с которыми работает система. Каталог обучающих множеств содержит описания обучающих множеств и ссылки на их обучающие примеры. Каталог классификаторов содержит описания классификаторов и ссылки на них самих и соответствующие им последовательности признаков. Каталог последовательностей признаков содержит их описания и ссылки на сами последовательности. Журнал предназначен для сохранении информации о состоянии базы знаний для поддержки ее целостности. Системные сообщения появляются на терминале пользователя в процессе диалога. Таким образом, имеется возможность изменить те или иные системные сообщения, например, их кодировку или язык при переносе системы. В настоящее время имеется два варианта системных сообщений - русский и английский.
5.5. Организация диалога
В процессе разработки системы нечеткого обучения были использованы алгоритмы редактирования строк, предложенные в работе [Каз87].
Диалог с пользователем основан на принципе объектно-ориентированного меню. Под объектной ориентированностью понима-ется то, что элементами меню являются не действия, которые можно произвести над некоторыми объектами, но сами объекты или, если точнее - имена этих объектов, назначаемые самим пользователем. Выбирая в меню объект, пользователь нажимает некоторую функциональную клавишу, определяющую действие, которое необходимо произвести над данным объектом. Так как набор действий невелик, их список, совместно с названиями функциональных клавиш, можно разместить в статусной строке. Таким образом, пользователь видит всю необходимую информацию и избавлен от двухэтапной процедуры выбора: сначала действие, потом объект. Объектами в системе являются признаки, обучающие множества, классификаторы и последовательности признаков. Последние определяют порядок проверки признаков классификатором.
В режиме меню экран разделен на три поля: поле объектов меню, поле статусной строки, поле подсказки. В последнем из перечисленных полей появляются пояснения о текущем объекте. Эти пояснения вводятся самим пользователем при создании нового объекта или системой, если меню статическое.
В ряде случаев используется двумерное меню, в котором поле объектов состоит из вертикальной и горизонтальной панелей. Например, при редактировании обучающего множества вертикальная панель содержит список признаков, а горизонтальная - номера обучающих примеров, тогда как оставшаяся часть поля объектов содержит, собственно объект - обучающий пример (распределение возможностей и необходимостей для данного признака).
Ниже приводится дерево меню системы нечеткого обучения.


5.6. Синтаксис входного языка
Для обеспечения совместимости с другими системами, в режиме редактирования обучающего множества предусмотрена возможность импортирования обучающих примеров из текстового файла. Файл импорта состоит из записей, каждая из которых может содержать обучающий пример. Ее формат:
<признак 1> <признак 2> ... <признак n> [;<комментарий>]
Для каждого признака его значение задается в виде неупорядоченного списка точек его области значений, разделенных запятыми. Для каждой точки области значения признака можно задать возможность и необходимость того, что она реализуется в значении признака. Формат этой конструкции следующий:
<точка области значений>[:<возможность>[:<необходимость>]]
Непример, если признак имеет область значений, состоящую из пяти точек, то его значение можно задать в виде:
1:1:0.5, 2:0.3, 3, 5:0.6:0.5 , что
соответствует распределениям возможностей 1:1, 2:0.3, 3:1, 4:0, 5:0.6 и необходимостей 1:0.5, 2:0, 3:0, 4:0, 5:0.5. Порядок следования точек области значений признака несущественен. Разделители могут быть окружены пробелами и табуляциями. Порядок следования признаков задается самим пользователем при выборе режима импорта в меню. При этом он может использовать последовательности признаков из каталога системы.
5.7. Оценка требуемого объема оперативной памяти
Настоящая версия системы нечеткого обучения построена таким образом, что обучающее множество не обязано находиться в оперативной памяти. Обучающие примеры подкачиваются в оперативную память по мере их надобности. Общее число резидентных в памяти обучающих примеров устанавливается при генерации комплекса. Стратегия замещения обучающих примеров - FIFO (первый подкачен, первый удален). Более сложные стратегии [Кей85] не были применены из-за высоких накладных расходов по их реализации. Таким образом, основным ограничивающим фактором является необходимость размещения в оперативной памяти самой граф-схемы. Оценим объем оперативной памяти необходимой для ее хранения.
Пусть N - количество признаков, |Di| - мощность области значений i-го признака, K - количество обучающих примеров. Легко убедиться, что полный граф, соответствующий граф-схеме, различает
ситуаций. То есть можно считать, что
Затраты памяти в байтах для хранения подобной граф-схемы в настоящей реализации системы составят:
где коэффициент 2 учитывает пару граф-схем (возможностей и необходимостей, |Dm| - наибольшая среди признаков мощность области значений, K - объем обучающего множества. Если положить, что |Dm|=1000, можно оценить K. Исходя из объема виртуальной памяти процесса в VAX/VMS, составляющего максимум 2 Гбайта [Кэп91], величина K составит число порядка 106. Таким образом, с практической точки зрения, объем обучающего множества ограничен только быстродействием.
5.8. Оценка производительности комплекса
Оценить расходы времени не представляется возможным из=за сложности алгоритма построения граф-схемы и разнообразных методов оптимизации, уменьшающих, с одной стороны, объем основных операций по построению граф-схемы, но, с другой стороны, вносящих свою долю в накладные расходы. Кроме того, объем вычислений в очень большой мере зависит от конкретного обучающего множества.
Основные оптимизации применяемые при построении граф-схемы:
Оценка производительности комплекса проводилась экспериментальным путем, на реальных обучающих множествах. При этом следует отметить относительность полученных результатов, связанную с тем, что:
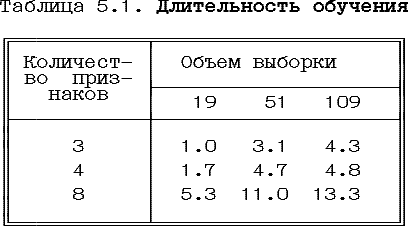
В таблице 5.1. приведена относительная длительность обучения при различном объеме обучающего множества и количестве используемых признаков. За единицу было выбрано время обучения на 19 обучающих примерах и 3 признаках, которое составляло, в зависимости от загруженности машины от 30 до 48 секунд на ЭВМ СМ-1700 с дисковым накопителем типа СМ-5408 и объемом реальной памяти 4Мбайт. При этом квота рабочего набора процесса равнялась 2000 страниц оперативной памяти. При использовании режима оптимизации при компиляции модулей системы это время уменьшалось до 20 секунд. Можно предположить, что при использовании режима оптимизации компилятора Ada и при подавлении языковых проверок, скорость работы существенно возрастет. Следует отметить, что производительность ЭВМ СМ-1700 на смеси Dhrystone (логические операции и передача управления) составляет 504 dhr/сек. Для сравнения, у IBM PC/AT (9МГц), производительность 1100 dhr/сек, а у micro VAX III - 5500 dhr/сек.
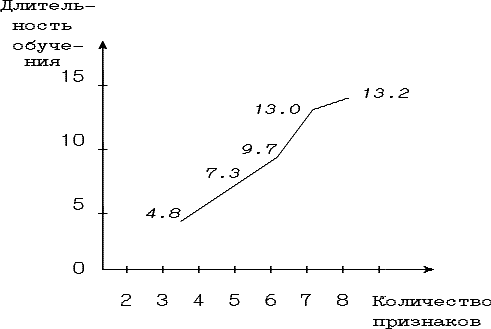
На рис.5.3. приведена зависимоть длительности процесса обучения от количества используемых признанов. Длительность обучения измерена в тех же единицах, что и в приведенной выше таблице.
Рис.5.3. Зависимоть продолжительности обучения от количества признанов
Видно, что время обучения нарастает практически линейно, хотя в общем случае, на произвольном обучающем множестве, время должно расти экспоненциально. Но на реальном обучающем множесте это соотношение нарушается из-за избыточности некоторых признаков и простой структуры классов.
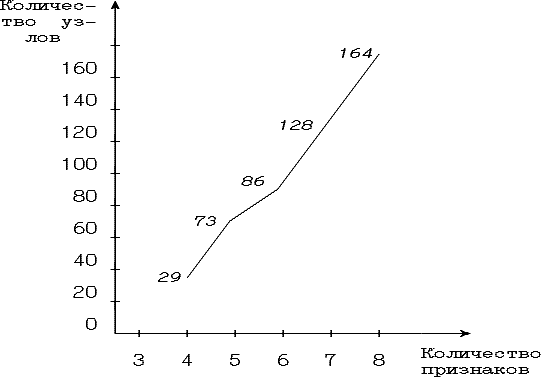
На рис. 5.4. приведена зависимость сложности граф-схемы от количества проверяемых признаков. Сложность граф-схемы определена, как количество составляющих ее узлов.
Рис. 5.4. Зависимость сложности граф-схемы от количества признаков
Зависимость времени распознавания от сложности граф-схемы, приведенной к количеству признаков, т.е. от величины
приводится в таблице 5.2.
Время измерялось относительно скорости обучения на 19 обучающих примерах по трем признакам. Имеется тенденция к увеличеню времени распознавания с ростом τ. Это означает, что увеличение количества узлов сильнее влияет на продолжительность распознавания, чем количество признаков. Зависимость близка к линейной, тогда как объем полного дерева растет экспоненциально. Следовательно, граф-схема растет скорее в глубину, нежели в ширину. Это вполне объяснимо, если принять во внимание ограниченность обучающего множества и количества классов.
5.9. Сравнение с известными методами обучения
Эксперименты по сравнению результатов работы системы нечеткого обучения с методами ГЕКОНАЛ и SEGAL [Геп85] проводились на наборе статистических данных, представляющих собой набор измерений ряда признаков. Метод обучения ГЕКОНАЛ относится к классу логических методов обучения. Образы классов строятся как набор так называемых миноров-эталонов, являющихся гиперплоскостями в пространстве описаний. Понятие минора-эталона близко к тупиковым тестам, используемых в алгоритмах АВО [Жур74, Гор85, Гор89]. Метод SEGAL представляет класс статистических методов обучения. В SEGAL используется модифицированный алгоритм типа ISODATA [Ту78].
Рассматривалась задача определения состояния механизма по признакам, представляющим собой акустические измерения в диапазоне звуковых частот. Такими признаками являются:
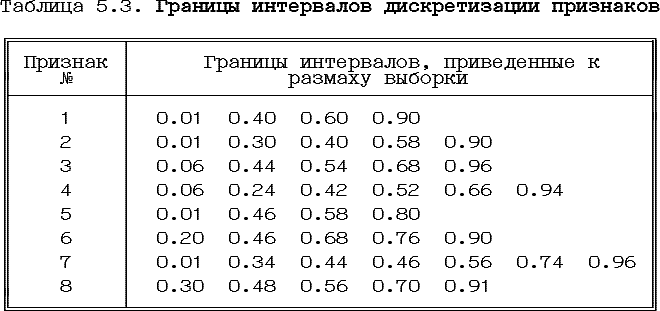
Всего использовалось 8 признаков. Данные составляли 355 векторов для двух классов источников акустического сигнала. Первый класс рассматривался как объект, находящийся в нормальном состоянии. Выборка данных данного класса состояла из 61-го вектора. Ко второму классу относились измерения, связанные с дефектным состоянием объекта (всего - 294 вектора). Для корректности результатов сравнения данные были дискретизованы одим и тем же способом для всех методов. В таблице 5.3. приведены границы интервалов дискретизации признаков:
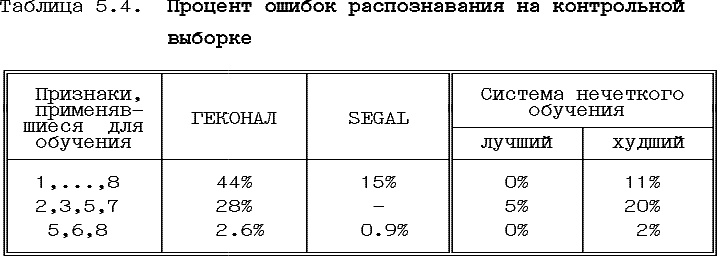
Обучение проводилось на 61-ом обучающем примере из первого класса и столько же из второго класса. 233 вектора составляли контрольную выборку, на которой проверялись результаты распознавания. В таблице 5.4. приведены результаты распознавания контрольной выборки после обучения на различных наборах признаков. В последних двух колонках таблицы находятся результаты работы системы нечеткого обучения для различных последовательностей проверки признаков. Худшие значения соответствуют наименее выгодной последовательности. Лучшие - случаю, когда наиболее информативные признаки проверяются первыми. Видно, что в худшем случае работа системы нечеткого обучения не уступает методу ГЕКОНАЛ.
Выигрыш по сравнению с методом ГЕКОНАЛ объясняется тем, что образы классов сложно построить из объединения гиперплоскостей, как это делается при использовании метода ГЕКОНАЛ, тогда как нечеткая граф-схема оказывается достаточно гибкой.
5.10. Выводы
1. Метод нечеткого обучения на основе граф-схем реализован в системе программирования языка Ada в операционной среде VAX/VMS.
2. На исследованной задаче предложенный метод по качеству обучения не уступает, а в ряде случаев превосходит известные методы обучения ГЕКОНАЛ и SEGAL.
3. Длительность обучения должна быть уменьшена.
4. Проблемой является порядок проверки признаков. При неудачном выборе порядка проверки, качество обучения может быть существенно хуже, чем в оптимальном случае. Таким образом, в практической работе необходимо исследование информативности признаков.